
I’ve been really excited and interested in level design recently, and reading a lot of work by folks like Robert Yang about lighting, space, and building worlds in 3D. It’s amazing stuff and it links in really well to the research I want to do right now (mostly because it’s influencing the research I want to do right now!) I wanted to write a little update about some work I did recently along these lines – building a level generator that uses in-game cameras to evaluate levels.
At FDG this year Gillian Smith presented a paper we wrote together about disrupting the field of automated game design and doing work that explores the less game-y, capital-V-Videogames elements of game design. In the paper I explained that I am hoping to build a new version of ANGELINA that generates games in a genre often referred to as walking simulators (although in the paper we discuss this term and offer up Joel Goodwin’s term, secret box). You can read the paper here, if you’re interested. This work is one of the first subsystems I’m building to be part of this new ANGELINA, and it’s all inspired by reading and listening to people talk about level design.
This is my first time condensing my own work in this way, especially not in a Saturday Papers format, so here goes. I’m going to use the classic breakdown that papers use: What Did I Do, Did It Work, What Am I Doing Next.
What I Did
I built a level generator in Unity that makes 3D levels while obeying certain rules. Normally when we build level generators we either don’t check the levels at all (think Spelunky), or we check them in quite cold functional ways, like exploration percentages. I was interested in how we could evaluate levels for other goals, like artistic or design objectives. A big thing that comes up when you read about level design is what the player sees, which is so beautifully obvious but also quite tricky to evaluate for computer scientists because it sounds a bit like machine vision might be involved and that’s scary and mysterious. I came up with a hacky middleground idea involving Unity cameras and raycasting and things like that but the long and short of it is this: I coded up my system so it can walk from the start to the exit and keep a record of everything it sees along the way.
After doing this, I placed special objects in the world called ‘markers’ and told the system to generate levels such that the markers were either seen a lot, a little, or not at all, depending on what kind of level I wanted.
Did It Work?
It did! Here’s a level with a red and a green marker, where both markers should be very visible.
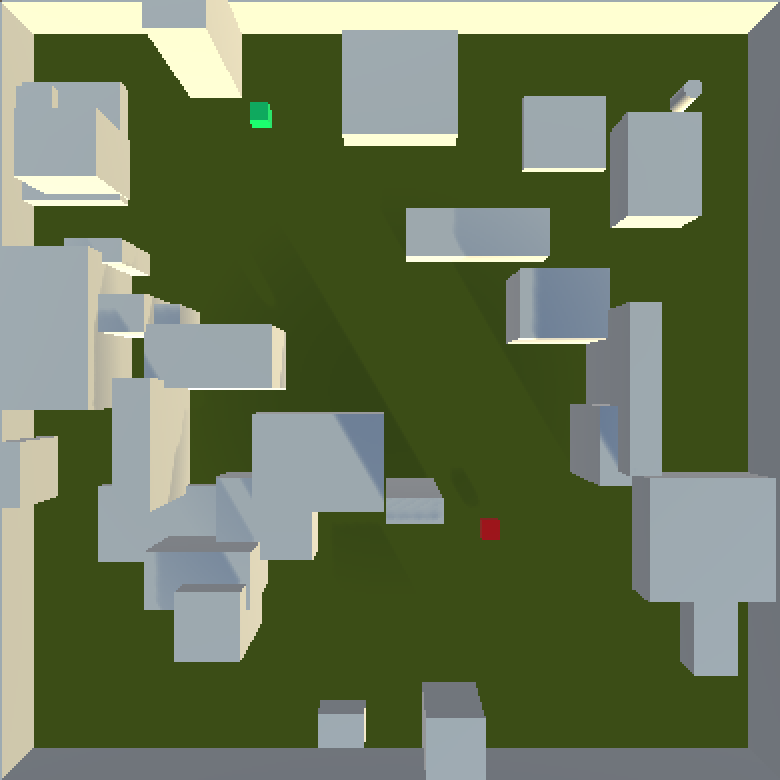
The player starts in the bottom left and has to reach the top right. You can see how the diagonal path makes both markers visible as the player makes their way to the exit. All these cubes are placed and scaled by the generator using our old friend computational evolution (the technique that powers ANGELINA). One more example, here’s a screenshot from a level that hides the red marker but makes the green one visible (again, we’re moving from bottom-left to top-right):

You might have seen me do a quick pilot study on Twitter last week – everyone correctly identified the markers that should be visible, and didn’t see any that could be hidden. It’s pretty easy to do this right now, but this was just an early study. The next step is to make the process more sophisticated and make the generative problem much harder.
What Am I Doing Next?
The system definitely evolves levels that obey the rules I set with the vision markers, but it’s not perfect. The main problems with the work are simply that it all needs to be made a bit more sophisticated. Here are some things that need expanding:
- A* Is Not Player Modelling – Currently the player just walks to the exit and perfectly pathfinds there every time. Funnily enough this is now how people work. I’m planning to replace this with a model that tries to capture visual curiosity – “Oh I haven’t been there before, I should go there next to look for the exit.” This should make level design much harder and more interesting.
- Cubes Are Not In Vogue – The cubes are okay for greyboxing, but in general we want to be using real 3D models because it’s more realistic for game developers. It’d be nice to give the system 10 models and have them used instead of cubes. This is high on the list of things to do next!
- Objectives or Zoning? – Visibility is tricky. Some markers are visible because the player sees them from a distance, others are visible because the player walks right past them up close. Some are invisible because they’re hidden, others are completely consumed by a larger geometry object. We need to distinguish between these cases by getting extra players objects to try and path towards the markers.
All of these areas should progress the system towards something interesting and relevant for the new version of ANGELINA!
It looks like a game, but It also resembles the designs of an architect. You can create this with Archicard. I would love to see this on my forum, great research anyways!
Haha, actually I think there’s a strong link here – I’m hoping to use something called Space Syntax on this project which I believe was developed by architects. Lots of parallels!
Interesting! I am working on a level generator for an Urban FPS using prefabs in Unity, houses, road pieces, props. This includes first steps to use raycasting in Unity’s physics engine to evaluate obstructions (or in other words: “cover” and “exposed areas”) based on the idea of ‘vision’.
Eventually, I’d like to use these agents not just for evaluation, but also as advanced AI bots, which are not just based on pathfinding and state machines (like nearly every NPC out there).
I am hoping to be in Paris in July 2016 to see your work at the conference!